データドリフト(Data Drift)の基礎概念と対策方法

1. イントロダクション
AIや機械学習モデルの運用において、モデルの予測精度が低下する原因として「ドリフト」があります。ドリフトは、モデルが学習した環境と運用時の環境に変化が生じた際に発生し、モデルのパフォーマンスに重大な影響を与えることがあります。本記事では、ドリフトの基本概念から、その発生パターン、データドリフトの詳細、そして、それを検知するための具体的な方法と対策について解説します。類似記事として、コンセプトドリフトについての解説も本サイトでしておりますので、併せてご覧ください。
目次
- イントロダクション
- ドリフトの定義
2-1. ドリフトとは
2-2. ドリフトの発生パターン - データドリフトの詳細説明
3-1. データドリフトの発生原因と具体例
3-2. データドリフトの定量化方法
3-3. データドリフトを認識する閾値の決め方
3-4. データドリフトが原因の失敗事例: LTCMの破綻 - データドリフトを抑制する方法
4-1. データドリフトを継続的に監視する
4-2. データドリフトが発生する前に、コンセプトドリフトの発生を予知する
4-3. モデルの定期的な再トレーニング - まとめ
2. ドリフト(Drift)の定義
2-1. ドリフト(Drift)とは
ドリフトとは、AIモデルがトレーニング時に学習したデータの特性や予測のコンセプトが、運用時に変化する現象を指します。これには、データドリフトとコンセプトドリフトの2つの主要な種類があります。
- データドリフト: トレーニングデータと運用データの分布が変化すること。
- コンセプトドリフト: モデルが学習した予測対象の本質や関係性が変化すること。
コンセプトドリフトにはさらに「Real Concept Drift(リアルコンセプトドリフト)」と「Virtual Drift(バーチャルドリフト)」があります。
- Real Concept Drift: 予測対象の本質的な関係が変化すること。たとえば、消費者の購買行動が長期間にわたり変化するケースがこれに該当します。
- Virtual Drift: データの分布が変化しないが、ノイズやランダムな要因によってモデルの出力が変化すること。たとえば、ある季節のみ特定の商品が異常に売れる場合などです。
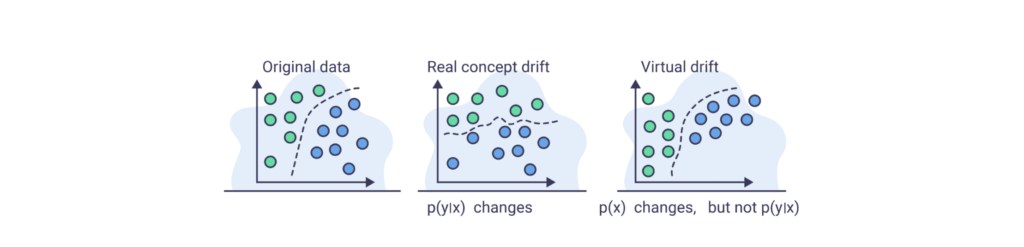
参考:https://www.aporia.com/blog/concept-drift-in-machine-learning-101/
2-2. ドリフト(Drift)の発生パターン
ドリフトの発生パターンは、データドリフトとコンセプトドリフトの有無に基づき、以下の4つに分類されます。これらのパターンは、Real Concept DriftとVirtual Driftの観点からも理解できます。
| Data Drift | Concept Drift | 状況の説明 |
|---|---|---|
| なし | なし | 正常状態: モデルが学習したコンセプトもデータ分布も変わらず、予測精度が保たれている状態 |
| あり | なし | Virtual Drift: データの分布が変わったが、予測対象の意味自体は変わっていない状態 |
| なし | あり | Real Concept Drift: 予測対象の意味やルールが変わるが、データ分布は変わらない状態 |
| あり | あり | Real Concept Drift: 予測対象の意味やルール、そしてデータの分布が共に変わる状態 |
3. データドリフト(Data Drift)の詳細説明
データドリフトは、AIモデルの運用において頻繁に発生する問題です。ここでは、データドリフトの発生原因、定量化方法、そしてそれを認識するための閾値の決め方について詳しく解説します。
3-1. データドリフトの発生原因と具体例
データドリフトが発生する原因は多岐にわたります。以下に、具体的な原因とその例を示します。
- 市場やユーザー行動の変化:
- 原因: 市場トレンドや消費者行動が変化
- 具体例: 季節商品(例:クリスマス関連商品)が特定の時期にのみ売れる場合、他の時期とは異なるデータ分布が生じます。
- データ収集方法の変更:
- 原因: センサーの精度向上や新しいデータ収集方法の導入による変化
- 具体例: 新しい顧客調査方法が導入された場合、以前の調査結果と比較して異なるデータ分布が生じる可能性があります。
- 外部要因の影響:
- 原因: 経済状況や規制の変更、自然災害など、外部要因によるデータの分布変化
- 具体例: 新型ウイルスの流行により、オンラインショッピングの利用が急増し、従来とは異なる購買パターンが見られるようになることがあります。
3-2. データドリフトの定量化方法
データドリフトを検知するためには、トレーニングデータと運用データの分布の違いを定量的に評価する必要があります。ここでは、代表的な2つの方法を紹介します。
3-2-1. KLダイバージェンスを用いた方法
KLダイバージェンスは、2つの確率分布間の違いを測定するための指標です。
- 数式: KLダイバージェンス \(D_{KL}\)は以下のように定義されます。ここで、\(P(i)\)はトレーニングデータの分布、\(Q(i)\)は運用データの分布を表します。$$ D_{KL}(P∥Q)=\sum_{i} P(i) \log\frac{P(i)}{Q(i)}$$
- メリット: 高い感度で分布の違いを検出できるため、ドリフトが生じた際に迅速に対応できる。
- デメリット: 計算が複雑で、大規模なデータセットに対して計算コストが高くなる。
- 適したケース: 明確なドリフトが発生している場合や、モデルの予測精度に直結する分布変化を検出したい場合に有効。
- 適さないケース: ノイズが多いデータセットや、微小なドリフトしか発生していないケースでは、誤検出のリスクが高い。
3-2-2. PSI(Population Stability Index)を用いた方法
PSI(Population Stability Index)は、2つのデータセットの分布の安定性を評価するための指標です。
- 数式: PSIは以下のように計算されます。ここで、\(A_i\)は観測された分布の割合、\(E_i\)は期待される分布の割合を示します。$$ PSI= \sum_{i} \left( \frac{A_i – E_i}{E_i} \right) \log \left( \frac{A_i}{E_i} \right) $$
- メリット: 計算が比較的容易であり、全体的な分布の変化を把握するのに適している。
- デメリット: 感度が低いため、微小なドリフトを検出することが難しい場合がある。
- 適したケース: データセット全体の安定性を評価し、急激な変化を検出したい場合に有効。
- 適さないケース: 細かい変化を早期に検出する必要がある場合には、他の方法と併用することが推奨される。
3-3. データドリフトを認識する閾値の決め方
データドリフトを検知するための閾値設定は、モデルの運用において重要なステップです。適切な閾値を設定することで、過剰反応を避けつつ、必要なアクションを取ることができます。
3-3-1. 統計的手法を用いた閾値設定
統計的手法では、データの自然な変動を考慮して信頼区間を設定し、その範囲を超えた場合にドリフトが発生したとみなします。これにより、データの揺らぎと実際のドリフトを区別できます。
3-3-2. ビジネスインパクトに基づいた閾値設定
ビジネスの影響を考慮して閾値を設定する方法もあります。例えば、売上や顧客満足度に重大な影響を与えるドリフトが検出された場合にのみアラートを出すように設定します。
3-4. データドリフトが原因の失敗事例: LTCMの破綻
データドリフトが適切に管理されなかった結果、重大な影響を受けた事例として、LTCM(Long-Term Capital Management)の破綻が挙げられます。LTCMは、複雑な金融モデルを用いて高い利益を上げていましたが、モデルが市場の急激な変動(データドリフト)に対応できず、大規模な損失を被り、最終的に破綻に至りました。このケースは、データドリフトを無視することのリスクを如実に示しています。
4. データドリフトを抑制する方法
データドリフトを抑制するためには、継続的なモニタリングやモデルの管理が不可欠です。ここでは、データドリフトを抑制するための具体的な方法を解説します。
4-1. データドリフトを継続的に監視する
データドリフトを早期に検知するためには、モデルが運用されている環境でリアルタイムモニタリングを行うことが重要です。定期的にデータ分布をチェックし、異常が検出された場合には迅速に対応することで、モデルの劣化を防ぐことができます。また、継続的な監視は時間枠を分割して行うことが効果的です。例えば、一日単位での監視では問題が発生しないが、時間単位での監視では問題が発生するケースでは、局所的な問題が起因していることになると仮定することができます。このように、ただリアルタイムモニタリングをすれば良い訳ではなく、そのモニタリング方法についても改善の余地があることを示唆してます。
4-2. データドリフトが発生する前に、コンセプトドリフトの発生を予知する
データドリフトが発生する前に、コンセプトドリフトの兆候を見つけることができれば、より早期に対策を講じることが可能です。これには、モデルの出力と実際の結果を定期的に比較し、予期せぬ変化が発生した場合にアラートを出す仕組みを導入することが有効です。
4-3. モデルの定期的な再トレーニング
データドリフトやコンセプトドリフトが発生した際には、モデルを再トレーニングすることが推奨されます。再トレーニングにより、最新のデータに適応したモデルを維持し、予測精度を高めることができます。再トレーニングの頻度は、業界やアプリケーションに応じて設定することが重要です。
5. まとめ
データドリフトとコンセプトドリフトは、AIモデルの運用において無視できない課題です。特に、データドリフトが発生していない場合でも、コンセプトドリフトのリスクを考慮し、モデルの継続的なモニタリングとメンテナンスが必要です。本記事で紹介した手法を活用して、AIモデルのパフォーマンスを最適化し、ビジネスリスクを最小限に抑えてください。




