生成AIのリスク軽減策:コンテンツフィルタリングとは

1.イントロダクション
生成AI(Generative AI)は、テキスト、画像、音声などの様々なコンテンツを自動で生成する技術で、多くの産業に変革をもたらしています。しかし、この技術にはさまざまなリスクが伴います。特に、Jailbreakによるモデルの意図しない挙動や、Toxicity(有害なコンテンツ)、ハルシネーション(Hallucination)と呼ばれる誤情報の生成が懸念されています。さらに、生成されたコンテンツが他者の著作権を侵害するリスクも無視できません。
これらのリスクを軽減するためには、コンテンツフィルタリングに加え、技術的なアプローチと統制手段の両方を組み合わせる必要があります。本記事では、生成AIにおけるリスク軽減策としてのコンテンツフィルタリングと、その導入方法、さらに技術的アプローチ以外の統制手段についても解説します。
Jailbreakについては以下の記事で解説をしております。併せてご参照ください。
2. 生成AIにおけるリスク軽減の重要性
生成AIを使用する際、さまざまなリスクが発生する可能性があります。これらのリスクを適切に管理するためには、生成AIが出力するコンテンツの品質を継続的に監視し、不適切な内容や誤情報の生成を防ぐ仕組みが不可欠です。特に、以下のリスクに注意が必要です。
- 不適切な表現の生成: AIが訓練データに含まれるバイアスを学習し、結果として差別的表現や攻撃的な言葉を生成するリスクがあります。こうしたコンテンツが公開されることで、企業の評判を損なう可能性があります。
- ハルシネーション(Hallucination): 生成AIが誤情報を生成する現象です。AIは確実性のない情報や存在しない事実を生成することがあり、これが誤解や混乱を招くリスクとなります。
- 著作権侵害: 生成AIが他の著作物を基にコンテンツを生成する場合、他者の著作権を侵害する可能性があります。これにより、法的な問題が発生するリスクが生じます。
- プライバシーやセキュリティリスク: AIが個人情報や機密情報を誤って生成・公開するリスクもあります。これはプライバシー侵害やデータ漏洩に繋がり、企業の信頼性に影響を与える可能性があります。
これらのリスクを軽減するためには、技術的な対策と運用における統制手段の両方を導入することが重要です。
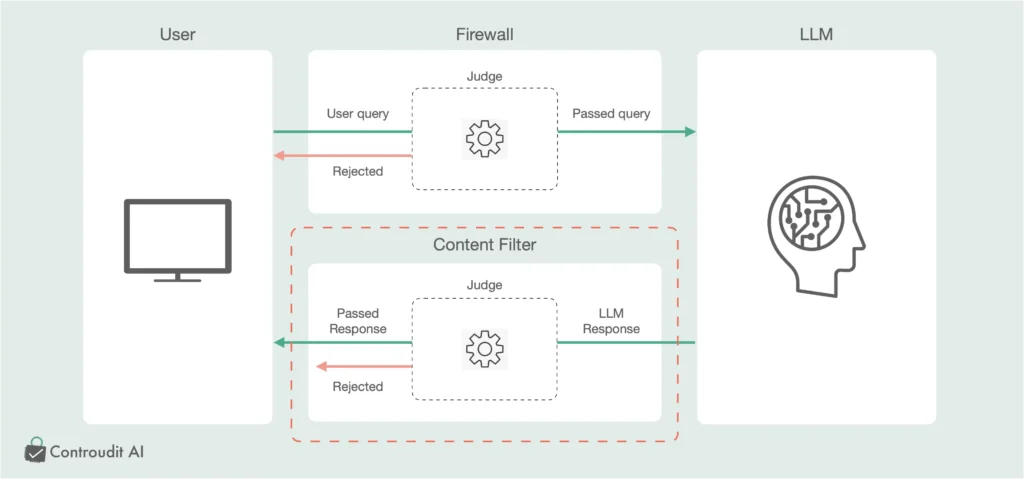
3. コンテンツフィルタリングとは
コンテンツフィルタリングは、生成AIが生成するコンテンツを監視し、不適切な内容や有害な情報を検出・除去するプロセスです。生成AIが生成するコンテンツには、toxicity(有害なコンテンツ)や攻撃的な言葉(offensive language)、ハルシネーションが含まれる可能性があるため、これらを事前にフィルタリングすることが必要です。
- キーワードベースのフィルタリング:事前に設定された禁止用語リスト(Banned Keywords List)に基づき、特定のキーワードやフレーズを検出するシンプルな手法です。これは、攻撃的な表現や差別的な言葉をリアルタイムでフィルタリングする際に有効です。
- 機械学習ベースのフィルタリング:キーワードベースのフィルタリングに加え、自然言語処理(NLP)を用いた機械学習ベースのフィルタリングも重要です。この手法は、文脈や意味を理解し、単なるキーワードでは検出できないトーン分析や感情分析を通じて、より高度なフィルタリングを実現します。
- トピックベースのフィルタリング:特定のトピックに関連するコンテンツが生成された際に、その内容を評価します。たとえば、教育コンテンツやニュースコンテンツで、暴力的なテーマやギャンブル関連の情報が含まれないように制御することが可能です。
- テキスト以外のフィルタリング:生成AIは、テキストに限らず、画像や音声といった他のメディアを生成することもあります。これらに対しても、適切なフィルタリングが必要です。注意点として、以下で述べる内容は不適切なコンテンツを検知するための手法であり、著作権の侵害を検知するものではない点です。著作権侵害を検知するための手法については、厳密に定義することが難しいため、現状は技術的な統制ではなく、利用規約にて著作権の考え方や、有事の際にどのように対処するかを記載することが推奨されています。
- 画像フィルタリング: コンピュータビジョン技術を活用し、画像内に不適切な内容が含まれていないかをチェックします。例えば、暴力的なシーンや違法なコンテンツを検出してフィルタリングします。
- 音声フィルタリング: 音声認識技術を利用して、音声内に有害な要素が含まれていないかを確認します。攻撃的な言葉や差別的表現が検出された場合には、それをフィルタリングします。
ただし、テキスト以外のメディアでは完全に不適切な内容を検出することが難しい場合があるため、**人間による監視(Human Review)**を組み合わせることが推奨されます。
4. 出力側の監視強化の重要性
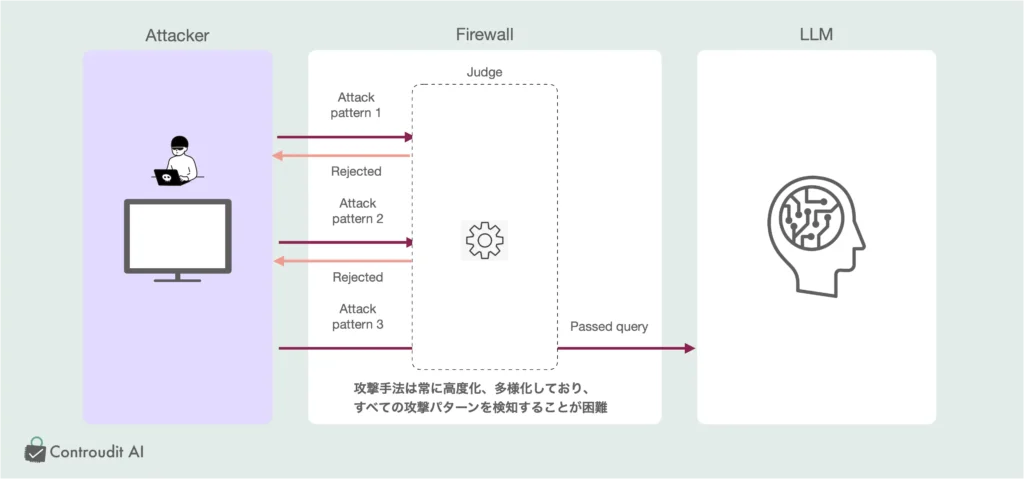
生成AIのセキュリティにおいては、入力側での攻撃検知を行うだけではなく、出力側の監視を強化することが非常に重要です。特に、生成AIに対する攻撃手法が高度化し続ける現代において、入力側での攻撃検知には限界があります。
4.1 入力側での攻撃検知の困難さ
- 攻撃手法の高度化と多様化: 現在のサイバー攻撃は、攻撃者が生成AIモデルに対して新しい手法を次々と開発しています。モデルに対する敵対的な攻撃(摂動攻撃や脱獄など)は、攻撃者が新たな技術やアルゴリズムを利用してモデルを操作するケースが増えています。このため、入力側での攻撃検知は、攻撃が変化し続ける限り非常に困難です。
- 入力側の監視は持続可能な解決策ではない: 攻撃手法が進化するたびに、検知アルゴリズムをアップデートし続けることは現実的ではなく、コストも増加します。つまり、入力側の検知には限界があり、これに依存するセキュリティ戦略は永続的な解決策にはなりにくいのです。
4.2 出力側の監視を強化する重要性
永続的な安定稼働のための出力監視: 出力側の監視は、モデルの安定した運用において長期的かつ効果的な対策となります。攻撃手法が進化しても、出力結果を監視し、予期せぬ挙動を検出することで、攻撃の結果を封じ込めることが可能です。これにより、システム全体の安全性と信頼性を保つことができ、長期間にわたり安定した運用が期待できます。
攻撃の影響を出力側で検出するアプローチ: 出力側の監視を強化することで、攻撃が成功した後でもモデルの異常な挙動を検出することが可能です。例えば、攻撃者がモデルを操作し、誤った出力や不適切な出力が生成された場合、出力側でその異常を迅速に検知して対策を講じることができます。これにより、攻撃の影響を最小限に抑えることが可能となります。
5. コンテンツフィルタリングの導入方法
コンテンツフィルタリングを効果的に導入するためには、APIベースのフィルタリングモデルやリアルタイム監視システムを組み合わせて使用することが推奨されます。ここでは、OpenAIが提供するフィルタリングソリューションを例に、具体的な導入方法を紹介します。
5-1. OpenAIのtext-moderationモデルの活用
OpenAIのtext-moderation-stableやtext-moderation-latestモデルは、生成されたテキストをリアルタイムで評価し、toxicityやハルシネーションを検出します。これらのモデルは、コンテンツがリアルタイムで生成される際に即座に評価を行い、不適切な出力を除去するために設計されています。
5-2. アプリケーションへの組み込み手順
- APIを利用した接続: OpenAIのAPIを通じて、生成AIの出力に対して自動的にフィルタリングを適用します。
- リアルタイムモニタリング: フィルタリングされた出力をリアルタイムで監視し、不適切なコンテンツが検出された場合には即時に対応します。
6. その他の統制手段によるリスク軽減
コンテンツフィルタリングだけでは、すべてのリスクを完全に軽減することはできません。そのため、技術的なアプローチに加えて、統制手段も併用することが重要です。
- 利用規約によるリスク軽減:生成AIを利用するシステムにおいては、利用規約に、著作権や不適切なコンテンツに関する明確なポリシーを記載しておくことが推奨されます。例えば、著作権侵害に関するリスクや、生成されたコンテンツの使用についての責任を明確にすることで、法的リスクを最小限に抑えることが可能です。
- 責任の所在を明確にする:生成AIが誤って不適切なコンテンツを出力した場合に、誰が責任を負うのかを明確にしておくことも重要です。企業は、システムの運用に関するコンプライアンスを徹底し、リスク発生時に責任の所在が不明瞭にならないように対策を講じるべきです。
7. まとめ
生成AIを安全に運用するためには、技術的な対策と統制手段の両方が必要です。以下の要点に基づき、リスク軽減策を整理していきます。
- 出力側の監視強化
- Jailbreak攻撃や摂動攻撃などの進化する攻撃手法に対応するには、出力側の監視が効果的です。
- 入力側での攻撃検知が困難であるため、生成されたコンテンツに対してリアルタイムで評価を行い、toxicityやハルシネーションといった問題を検出する仕組みが必要です。
- コンテンツフィルタリングの導入
- OpenAIのtext-moderationモデルを使用してリアルタイムでフィルタリングを実施し、差別的表現や不適切なトーンを即座に除去します。
- テキスト以外のメディアに対しても、画像や音声のフィルタリング技術を適用し、人間のレビューを組み合わせることでさらに精度を高めることができます。
- 統制手段の併用
- 利用規約に著作権や不適切なコンテンツ生成の責任について明確に記載し、リスクが発生した場合の対応を事前に定めておくことが重要です。
- 責任の所在を明確にし、誤ったコンテンツが出力された場合でも、迅速に対応できる体制を整備します。
- 長期的なガバナンス体制
- モデルの定期的な再学習やフィルタリング技術のアップデートを実施し、生成AIのリスク管理を継続的に強化することが重要です。
- 透明性を高め、ユーザーに対してAIが生成するコンテンツのリスクや対策を明確に説明することで、信頼関係を構築します。
これにより、企業は生成AIのリスクを最小限に抑え、安定した運用を実現するための体制を整えることができます。特に、技術的なアプローチとガバナンス、統制手段を組み合わせることで、長期的かつ安全なAI運用が可能となるでしょう。




