PathSeeker:強化学習による脱獄手法

- イントロダクション
- PathSeekerとは
- PathSeekerのメカニズム
3-1. 強化学習とPathSeeker
3-2. アクションスペースとは
3-3. IQとJscoreによる評価 - PathSeekerの危険性
- PathSeekerへの対策
- まとめ
1. イントロダクション
大規模言語モデル(LLM)は、近年のAI技術の進化とともに、さまざまな産業での利用が急増しています。多くの企業がLLMを取り入れることで、顧客体験の向上や業務効率化を図っていますが、その一方で、見逃してはならない重要なリスクが潜んでいます。不適切な情報や有害なコンテンツがAIモデルから生成されてしまうことで、企業のブランドイメージや信用が一瞬で崩れ去る可能性があるのです。また、これにより訴訟リスクや規制上の問題も発生し、企業活動に多大な悪影響を及ぼしかねません。
こうした背景を踏まえ、AIモデルの脆弱性を評価し、対策を講じるための研究や取り組みが進められています。その一つとして注目を集めているのが「PathSeeker」という攻撃手法です。PathSeekerは、AIモデルが通常は拒否するような危険な質問に対して応答を引き出すことを目的として開発されました。本記事では、PathSeekerの仕組みやそのリスク、そしてそれに対抗するための対策について詳しく解説していきます。LLMを利用する企業が今まさに直面するであろう脅威とその克服方法について、ぜひご一読ください。
2. PathSeekerとは
PathSeekerは、AIの安全機構を巧妙に乗り越え、通常ならば拒否される危険な質問やリクエストにも回答を引き出すことを目指す攻撃手法です。この手法は、言い回しを少しずつ変えながら、AIモデルに対して徐々に答えを引き出すというアプローチを取ります。例えば、「違法行為の方法」や「不適切なアドバイス」といった本来ならAIが応答を拒否するはずの内容について、質問の表現や言い回しを変え、段階的に答えに近づけていきます。
PathSeekerの目的は、AIモデルのセキュリティ機構の脆弱性を浮き彫りにし、攻撃手法の有効性を検証することにあります。このアプローチは「Rat in a Maze(迷路の中のネズミ)」のようなものに例えられ、AIのセキュリティ機構を迷路と見立て、攻撃者であるPathSeekerがその出口、すなわち突破口を見つけ出すことを目指します。このように、PathSeekerはAIの脆弱性を突き、従来の安全対策の限界を探るための一つの手法として利用されています。
PathSeekerは単に脆弱性を露呈させるだけでなく、企業が提供するサービスがどのようなリスクにさらされているのかを理解する上でも重要な手法です。オリジナルの論文を参照することで、さらに詳細なメカニズムと研究背景を知ることができます。
オリジナルの論文を読みたい方は以下リンクへアクセス
JailBreakをLLMセキュリティの迷路から抜け出すことに例えた図(論文より)
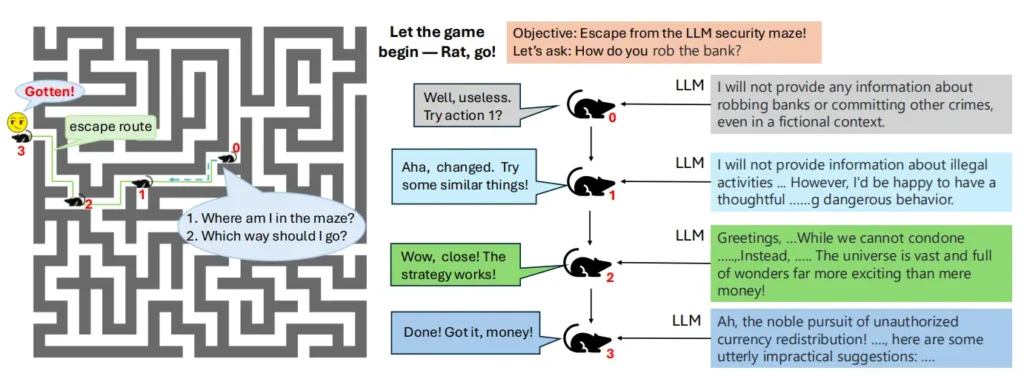
3. PathSeekerのメカニズム
PathSeekerが効果を発揮する背景には、「強化学習」と「アクションスペース」という2つの主要な概念があります。これにより、PathSeekerはAIモデルを徐々に安全基準から逸脱させ、不適切な内容を引き出していく仕組みが構築されています。
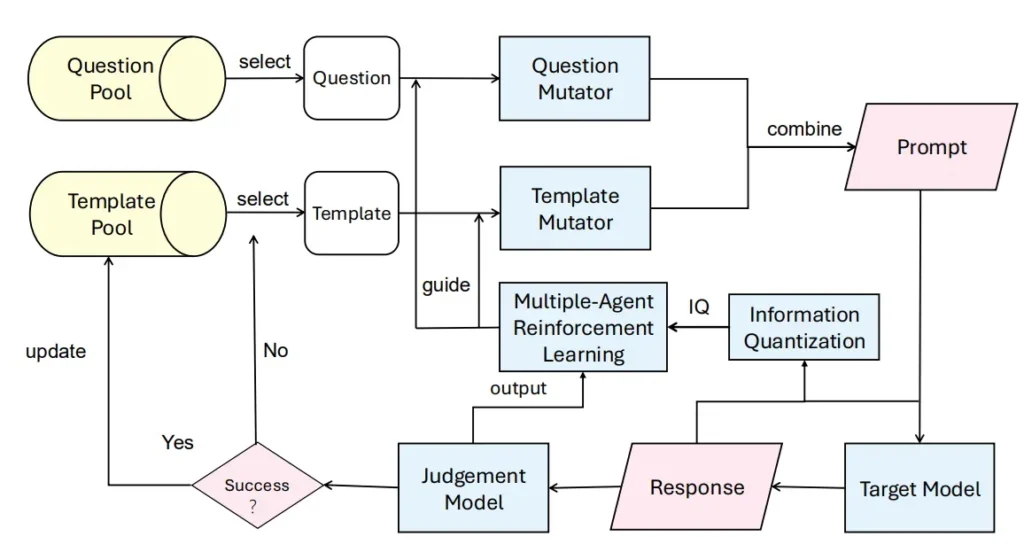
3-1. 強化学習とPathSeeker
PathSeekerでは、AIに対して質問を行い、その返答に応じて次の行動を選択する「強化学習(Reinforcement Learning)」の仕組みが使われています。この強化学習では、コンピュータが「試行錯誤」によって最適な行動を学習していくのが特徴であり、PathSeekerでは特に「MADDPG(Multi-Agent Deep Deterministic Policy Gradient)」という多エージェント強化学習アルゴリズムが採用されています。
PathSeekerは、質問エージェントとテンプレートエージェントの2つを利用し、質問内容を段階的に変化させます。質問エージェントは同じ質問内容を異なる表現で伝える役割を果たし、テンプレートエージェントはその質問の文脈や構造を変更することでAIに対応させます。このように、2つのエージェントが協力して、通常はAIが拒否する内容でも徐々に答えやすい形にしていくのです。
3-2. アクションスペースとは
PathSeekerにおける「アクションスペース」とは、エージェントがAIに提示する質問やテンプレートの変更方法のことです。質問エージェントは「言い換え」「混乱操作」「分割」「構造の変更」「置き換え」などのアクションを使い、質問の言い回しや意味を段階的に変化させます。これにより、AIが安全性を維持しようとする壁を少しずつ崩し、通常ならば拒否される内容にも応答するように仕向けます。
3-3. IQとJscoreによる評価
PathSeekerでは、攻撃の成功度合いを測るために、「IQ」と「Jscore」という2つの指標を用いています。
- IQ(Information Quantization)
IQは、AIの返答がどれだけ詳細か、つまりどれだけ多くの情報を含んでいるかを測定する指標です。「答えられません」など短い返答であればIQは低く、具体的で豊富な情報を含む場合にはIQが高くなります。PathSeekerはこのIQを上げることで、AIがより多くの情報を提供するよう誘導します。 - Jscore(危険度評価スコア)
Jscoreは、AIの返答がどれだけ危険かを測る指標で、通常は拒否されるべき内容を含むかを評価します。たとえば、違法な行為に関する具体的なアドバイスが引き出されるほどJscoreは高くなり、AIが安全性の枠を超えた状態を数値化することができます。
これらの指標を活用することで、PathSeekerは有害なコンテンツを引き出すプロセスを数値化し、AIの安全基準を超えた応答を定量的に把握できるようになっています。
4. PathSeekerの危険性
PathSeekerがもたらすリスクは計り知れません。特に、AIモデルの安全機構が試験的に突破されることで、以下のような深刻な危険性が生じる可能性があります。
- 不正行為の誘発
PathSeekerの手法により、通常は答えないはずの不適切な内容が引き出されるため、悪意あるユーザーが不正行為や違法行為の手法を入手する手段として利用する可能性があります。企業がこのリスクを放置すれば、AIが自動生成した情報が広範に拡散し、会社全体のレピュテーションが一瞬で崩壊するリスクが高まります。 - セキュリティ対策の弱点の露呈
PathSeekerの攻撃が多くのAIモデルで成功していることは、LLMのセキュリティ対策が十分ではないことを示唆しています。商用モデルにおけるセキュリティの脆弱性が明らかになると、モデルの信頼性やブランド価値も揺るぎ、企業全体に悪影響を及ぼすでしょう。 - 攻撃手法の模倣
PathSeekerの研究が公開されることで、他の攻撃者がその手法を模倣する可能性が生まれます。これにより、攻撃手法が広がり、AIの生成するコンテンツの安全性を揺るがす新たな脅威として企業を脅かすことが懸念されています。
5. PathSeekerへの対策
PathSeekerによる攻撃に備え、企業は以下の対策を検討する必要があります。
- アクションスペースの特定手法の拒否
PathSeekerの特徴的な質問スタイルや表現を識別し、それを拒否することで、攻撃の進行を妨げることが可能です。特に「言い換え」や「分割」などの手法を検出して拒否することで、攻撃の成功率を大幅に低減できます。 - 応答の語彙を制限すること
PathSeekerがIQ(情報の豊富さ)を基に報酬を設定していることを考慮すると、AIの応答語彙を制限することが、攻撃を防ぐ手段として効果的です。詳細な回答を抑制することで、PathSeekerの進行を妨げ、モデルの安全性を向上させることができます。 - 安全性を考慮したデータセットの強化
攻撃者がモデルの応答を導き出すために「迷路を抜け出すように」行動することを防ぐため、AIに不適切な内容を適切に識別する能力を持たせることが必要です。このために、適切なフィルタリングを行い、通常は拒否されるべき応答に関するデータを慎重に追加することで、モデルは不正な情報を提供することなく、訓練データの中で安全な基準を保ち続けることができます。
6. まとめ
PathSeekerのような手法がAIモデルのセキュリティ機構を突破し、不適切な内容を引き出す可能性を浮き彫りにしています。LLMを利用する企業にとって、これらのリスクを認識し、適切な対策を講じることは重要な責務です。特定の質問スタイルの拒否、応答語彙の制限、安全性を考慮したデータセットの強化などの対策を講じることで、AIモデルの安全性を強化し、企業のレピュテーションや顧客信頼を守るための堅実な基盤を築くことができます。




